30 Days of ML with Kaggle [Day 12]-Introduction, Missing Values, Categorical Variables
오늘은 Day 12 이다.
Intro to ML을 끝내고, Intermediate ML course을 시작한다.
Today's Assignment - day 12
- Read this tutorial (from Lesson 1 of the Intermediate ML course)
- Complete this exercise (from Lesson 1 of the Intermediate ML course)
- Read this tutorial (from Lesson 2 of the Intermediate ML course)
- Complete this exercise (from Lesson 2 of the Intermediate ML course)
- Read this tutorial (from Lesson 3 of the Intermediate ML course)
- Complete this exercise (from Lesson 3 of the Intermediate ML course)

Introduction
kaggle learn의 중급 machine_learning 과정이다.
이 과정에서는 다음과 같은 방법을 학습하여 machine_larning 지식을 가속화 할 수 있다.
- 실제 데이터 세트에서 자주 발견되는 데이터 유형(결측값, 범주형 변수)
- machine_learning 코드의 품질을 개선하기 위한 설계 파이프라인
- cross_validation(교차 검증)을 위한 고급 기법 사용
- Kaggle대회에서 우승하는데 널리 사용되는 최첨단 모델을 구축
- 일반적이고 중요한 데이터 사이언스 실수 방지(leakage)-데이터 누수
이 과정에서 새로운 주제별로 실제 데이터로 실습활동을 완료하여 지식을 강화할 수 있다.
실습은 Kaggle Learn Users를 위한 주택가격 competition의 데이터를 사용하여 79개의 설명 변수(지붕 유형, 침실 수, 욕실수 등)을 사용하여 집값을 예측한다.

Prerequisites
이전에 machine_learning 모델을 구축한 적이 있고 모델 검증, 언더핏 및 오버핏, 랜덤 포레스트와 같은 주제에 익숙하다면 이 micro과정을 수강할 준비가 되어있는 것이다.
해당과정의 exercise를 수행해 보자.
Setup
# Set up code checking
import os
if not os.path.exists("../input/train.csv"):
os.symlink("../input/home-data-for-ml-course/train.csv", "../input/train.csv")
os.symlink("../input/home-data-for-ml-course/test.csv", "../input/test.csv")
from learntools.core import binder
binder.bind(globals())
from learntools.ml_intermediate.ex1 import *
print("Setup Complete")
데이터를 import 해주었다.

import pandas as pd
from sklearn.model_selection import train_test_split
# Read the data
X_full = pd.read_csv('../input/train.csv', index_col='Id')
X_test_full = pd.read_csv('../input/test.csv', index_col='Id')
# Obtain target and predictors
y = X_full.SalePrice
features = ['LotArea', 'YearBuilt', '1stFlrSF', '2ndFlrSF', 'FullBath', 'BedroomAbvGr', 'TotRmsAbvGrd']
X = X_full[features].copy()
X_test = X_test_full[features].copy()
# Break off validation set from training data
X_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.8, test_size=0.2,
random_state=0)그리고, 사이킷런의 "train_test_split"을 이용해서 train 데이터를 train과 validation 데이터로 나눠주었다. random_state는 0으로 지정했다.
X_train.head()
X_train data를 확인했다.
from sklearn.ensemble import RandomForestRegressor
# Define the models
model_1 = RandomForestRegressor(n_estimators=50, random_state=0)
model_2 = RandomForestRegressor(n_estimators=100, random_state=0)
model_3 = RandomForestRegressor(n_estimators=100, criterion='mae', random_state=0)
model_4 = RandomForestRegressor(n_estimators=200, min_samples_split=20, random_state=0)
model_5 = RandomForestRegressor(n_estimators=100, max_depth=7, random_state=0)
models = [model_1, model_2, model_3, model_4, model_5]모델을 생성해주었는데, 하이퍼파라미터를 조정해서 5개의 모델을 생성했다.
그리고 models라는 변수에 리스트로 담아주었다.
from sklearn.metrics import mean_absolute_error
# Function for comparing different models
def score_model(model, X_t=X_train, X_v=X_valid, y_t=y_train, y_v=y_valid):
model.fit(X_t, y_t)
preds = model.predict(X_v)
return mean_absolute_error(y_v, preds)
for i in range(0, len(models)):
mae = score_model(models[i])
print("Model %d MAE: %d" % (i+1, mae))
모델의 MAE를 구하여 출력했다.
model_3가 MAE가 가장 낮게 나온 것을 확인했다.
Step 1: Evaluate several models
best_model = model_3mode_3를 best_model이라는 변수에 담아주었다.
Step 2: Generate test predictions
# Define a model
my_model =best_model # Your code here사용할 모델을 my_model이라고 정하고 best_model을 지정해주었다.
# 각 피쳐의 중요도 확시각화
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
ftr_importances_values = best_model.feature_importances_
ftr_importances = pd.Series(ftr_importances_values, index = X_train.columns)
ftr_top20 = ftr_importances.sort_values(ascending=False)[:20]
plt.figure(figsize=(8,6))
plt.title('Top 20 Feature Importances')
sns.barplot(x=ftr_top20, y=ftr_top20.index)
plt.show()
각 피쳐의 중요성 시각화하여 확인해 보았다.
# Fit the model to the training data
my_model.fit(X, y)
# Generate test predictions
preds_test = my_model.predict(X_test)
# Save predictions in format used for competition scoring
output = pd.DataFrame({'Id': X_test.index,
'SalePrice': preds_test})
output.to_csv('submission.csv', index=False)my_model에 피팅하여 예측을 수행했다. 그리고 output은 ID는 X_test의 index를 담았고, SalePrice에 test데이터에 대한 예측을 담았다.
csv로 저장하여 submission을 제출했다.
Submit your results

해당 excercise를 정리한 코드를 공유한다!
https://github.com/mgkim-developer/30-Days-of-ML-with-Kaggle/blob/main/30-days-of-ml-day-12-introduction.ipynb
GitHub - mgkim-developer/30-Days-of-ML-with-Kaggle: 30 Days of ML with Kaggle
30 Days of ML with Kaggle. Contribute to mgkim-developer/30-Days-of-ML-with-Kaggle development by creating an account on GitHub.
github.com
Missing Values
이 튜토리얼에서는 결측값을 처리하는 세 가지 방법을 배울 것이다.
그런 다음 실제 데이터셋에서 이러한 접근 방식의 효과를 비교할 수 있다.
Introduction
데이터가 결측값으로 끝날 수 있는 방법에는 여러가지가 있다. 예를들면,
- 침실이 2개인 주택에는 세 번쨰 침실의 크기 값이 포함되지 않는다.
- 설문 응답자는 자신의 소득을 공유하지 않기로 선택할 수 있다.
대부분의 machine_learning 라이브러리(scikit-learn 포함)는 결측값이 있는 데이터를 사용하여 모델을 구축하려고 하면 오류가 발생한다. 따라서 아래 전략 중 하나를 선택해야 한다.
Three Approaches
1) A Simple Option: 결측값이 있는 열 삭제
가장 간단한 옵션은 결측값이 있는 열을 삭제하는 것이다.

삭제된 열의 대부분의 값이 누락되지 않는 한, 이 접근 방식을 사용하면 모델이 많은(잠재적으로 유용한) 정보에 액세스 할 수 없게 된다.
극단 적인 예로, 10,000개 행이 있는 데이터세트가 있다고 가정해보겠다. 여기서 중요한 열 하나에 단일 항목이 누락되어있다면, 이 접근 방식은 열을 완전히 삭제한다!
2) A Better Option: Imputation (대치 귀속)
imputation은 누락된 값을 일부 숫자로 채운다.
예를 들어, 각 열을 따라 평균 값을 채울 수 잇다.

대부분의 경우 imputation 된 값은 정확하게 맞지는 않지만, 일반적으로 열을 완전히 삭제하여 얻을 수 있는 것보다 더 정확한 모델을 얻을 수 있다.
3) An Extension To Imputation (대치 귀속의 연장)
imputation은 표준 접근 방식이며, 일반적으로 잘 작동한다.
그러나 imputation(대치)된 값은 데이터세트에서 수집되지 않은 실제 값보다 체계적으로 높거나 낮을 수 있다.
또는 결측값이 있는 행은 다른방식으로 고유할 수 있다.
이 경우 모델은 원래 결측값인 값을 고려하여 더 나은 예측을 수행한다.

이 접근 방식에서는 이전과 같이 결측값을 imputation( 대치 귀속)한다.
또한 원래 데이터 세트에서 누락된 항목이 있는 각 열에 대해 imputation 항목의 위치를 표시하는 새 열을 추가한다.
어떤 경우에는 결과가 의미 있게 향상되지만, 전혀 도움이 되지 않는 경우도 있다.
Example
예시에서는 멜버른 하우징 데이터셋으로 작업하겠다.
모델은 객실수, 대지 크기 등의 정보를 이용하여 집값을 예측할 것이다.
import pandas as pd
from sklearn.model_selection import train_test_split
# Load the data
data = pd.read_csv('../input/melbourne-housing-snapshot/melb_data.csv')
# Select target
y = data.Price
# To keep things simple, we'll use only numerical predictors
melb_predictors = data.drop(['Price'], axis=1)
X = melb_predictors.select_dtypes(exclude=['object'])
# Divide data into training and validation subsets
X_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.8, test_size=0.2,
random_state=0)Define Function to Measure Quality of Each Approach
각 접근의 품질을 측정하기 위해 함수를 정의한다.
결측값 처리에 대한 다양한 접근 방식을 비교하기 위해 함수 score_dataset()를 정의한다.
이 함수는 랜덤 포레스트 모델의 평균 절대오차(MAE)를 return한다.
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error
# Function for comparing different approaches
def score_dataset(X_train, X_valid, y_train, y_valid):
model = RandomForestRegressor(n_estimators=10, random_state=0)
model.fit(X_train, y_train)
preds = model.predict(X_valid)
return mean_absolute_error(y_valid, preds)Score from Approach 1 (Drop Columns with Missing Values)
train data set 및 validation data set을 모두 사용하고 있으므로 두 데이터 프레임에서 동일한 열을 삭제하도록 주의하자. ###매우 중요
# Get names of columns with missing values
cols_with_missing = [col for col in X_train.columns
if X_train[col].isnull().any()]
# Drop columns in training and validation data
reduced_X_train = X_train.drop(cols_with_missing, axis=1)
reduced_X_valid = X_valid.drop(cols_with_missing, axis=1)
print("MAE from Approach 1 (Drop columns with missing values):")
print(score_dataset(reduced_X_train, reduced_X_valid, y_train, y_valid))
Score from Approach 2 (Imputation)
다음으로 SimpleImputer을 사용하여 결측값을 각 열의 평균값으로 대체한다.
단순하지만 평균 값을 입력하면 일반적으로 성능이 상당히 향상된다.(데이터세트에 따라 다르긴함)
통계학자들은 귀속값(imputed values)를 결정하기 위해 보다 복잡한 방법(예: regression imputation[회귀 귀속])을 실험했지만 복잡한 전략은 정교한 machine_learning 모델에 결과를 연결하면 일반적으로 추가적인 이점을 제공하지 않는 것을 확인했다.
from sklearn.impute import SimpleImputer
# Imputation
my_imputer = SimpleImputer()
imputed_X_train = pd.DataFrame(my_imputer.fit_transform(X_train))
imputed_X_valid = pd.DataFrame(my_imputer.transform(X_valid))
# Imputation removed column names; put them back
imputed_X_train.columns = X_train.columns
imputed_X_valid.columns = X_valid.columns
print("MAE from Approach 2 (Imputation):")
print(score_dataset(imputed_X_train, imputed_X_valid, y_train, y_valid))
접근 방식 2가 접근 방식 1 보다 MAE가 낮으므로 이 데이트 세트에서 접근 방식 2가 더 잘 수행되었음을 알 수 있다.
Score from Approach 3 (An Extension to Imputation)
다음접근법으로, 누락된 값을 대치하면서 어떤 값이 대치되었는지 추적한다.
# Make copy to avoid changing original data (when imputing)
X_train_plus = X_train.copy()
X_valid_plus = X_valid.copy()
# Make new columns indicating what will be imputed
for col in cols_with_missing:
X_train_plus[col + '_was_missing'] = X_train_plus[col].isnull()
X_valid_plus[col + '_was_missing'] = X_valid_plus[col].isnull()
# Imputation
my_imputer = SimpleImputer()
imputed_X_train_plus = pd.DataFrame(my_imputer.fit_transform(X_train_plus))
imputed_X_valid_plus = pd.DataFrame(my_imputer.transform(X_valid_plus))
# Imputation removed column names; put them back
imputed_X_train_plus.columns = X_train_plus.columns
imputed_X_valid_plus.columns = X_valid_plus.columns
print("MAE from Approach 3 (An Extension to Imputation):")
print(score_dataset(imputed_X_train_plus, imputed_X_valid_plus, y_train, y_valid))
우리가 볼 수 있듯이, 접근 3은 접근 2보다 약간 더 나쁜 성능을 보였다.
그렇다면, 왜 imputation의 성능은 결측값이있는 column을 삭제한 것의 성능보다 더 좋을까?
train_data에는 10864개의 행과 12개의 열이 있으며, 3개의 열에 결측데이터가 포함되어 있다.
각열에 대해 결측된 항목이 절반 미만이다.
따라서 열을 삭제하면 유용한 정보가 많이 제거되므로 imputation 접근법이 결측값이있는 열을 제거하는 접근법보다 성능이 더 좋다.
# Shape of training data (num_rows, num_columns)
print(X_train.shape)
# Number of missing values in each column of training data
missing_val_count_by_column = (X_train.isnull().sum())
print(missing_val_count_by_column[missing_val_count_by_column > 0])
Conclusion
흔히 볼 수 있듯,(접근법 2와 접근법3)에서 결측값을 imputation(귀속)시키면 결측값이 있는 열을 단순히(접근법1) 삭제했을 때보다 더 나은 결과를 얻을 수 있었다.
위의 실습을 excercise를 통해 직접 수행해 보자!
실습하며 정리한 코드를 공유한다!
https://github.com/mgkim-developer/30-Days-of-ML-with-Kaggle/blob/main/30-days-of-ml-day-12-missing-values.ipynb
GitHub - mgkim-developer/30-Days-of-ML-with-Kaggle: 30 Days of ML with Kaggle
30 Days of ML with Kaggle. Contribute to mgkim-developer/30-Days-of-ML-with-Kaggle development by creating an account on GitHub.
github.com
이번에는 범주형 변수를 다루는 방법에 대해서 알아 볼 것이다.
Categorical Variables
이 튜토리얼에서는 범주형 변수가 무엇인지, 이러한 유형의 데이터를 처리하는 세 가지 접근 방식에 대해 알아볼 것이다.
Introduction
범주형 변수는 제한된 수의 값만 사용한다.
- 아침을 얼마나 자주 먹는지 묻고 "Never", 'Rarely', 'Most days', or 'Every day'의 네 가지 옵션이 제공되는 설문조사를 고려해보자. 이 경우, 응답이 고정된 범주 집합에 속하기 때문에 데이터는 범주형이다.
- 만약, 사람들이 어떤 브랜드의 자동차를 소유하고 있는지에 대한 설문조사에 응답한다면, 응답은 'Honda', 'Toyota', and 'Ford' 와 같은 범주로 분류된다. 이 경우의 데이터도 범주형이다.
이러한 변수를 사전에 먼저 처리하지 않고 Python의 대부분의 machin_learning 모델에 연결하려고 하면 오류가 발생한다. 이 튜토리얼에서는 범주형 데이터를 준비하는데 사용할 수 있는 세 가지 방법을 비교한다.
Three Approaches
1) Drop Categorical Variables (범주형 변수 삭제)
범주형 변수를 처리하는 가장 쉬운 방법은 데이터 집합에서 변수를 제거하는 것이다.
이 접근 방식은 column(열)에 유용한 정보가 없는 경우에만 잘 작동한다.
2) Ordinal Encoding (서수 인코딩)
서수 인코딩은 각 고유 값을 다른 정수에 할당한다.

이 접근법은 범주의 순서를 가정한다.
"Never" (0) < "Rarely" (1) < "Most days" (2) < "Every day" (3)
이 가정은 범주에 대해 논쟁의 여지가 없는 순위가 있기 때문에 이 예에서 의미가 있다.
모든 범주형 변수가 값에서 명확한 순서를 갖는 것은 아니지만, 이것을 순서형 변수라고 한다.
트리 기반 모델(예: 의사결정나무, 랜덤포레스트)의 경우 Ordinal Encoding(서수 인코딩)이 ordinal variables(서수 변수)와 잘 작동할 것으로 기대할 수 있다.
3) One-Hot Encoding (원-핫 인코딩)
One-hot 인코딩은 원본 데이터에서 가능한 각 값의 존재(또는 부재)를 나타내는 새 열을 생성한다.
이것을 이해하기 위해 예제를 수행할 것이다.
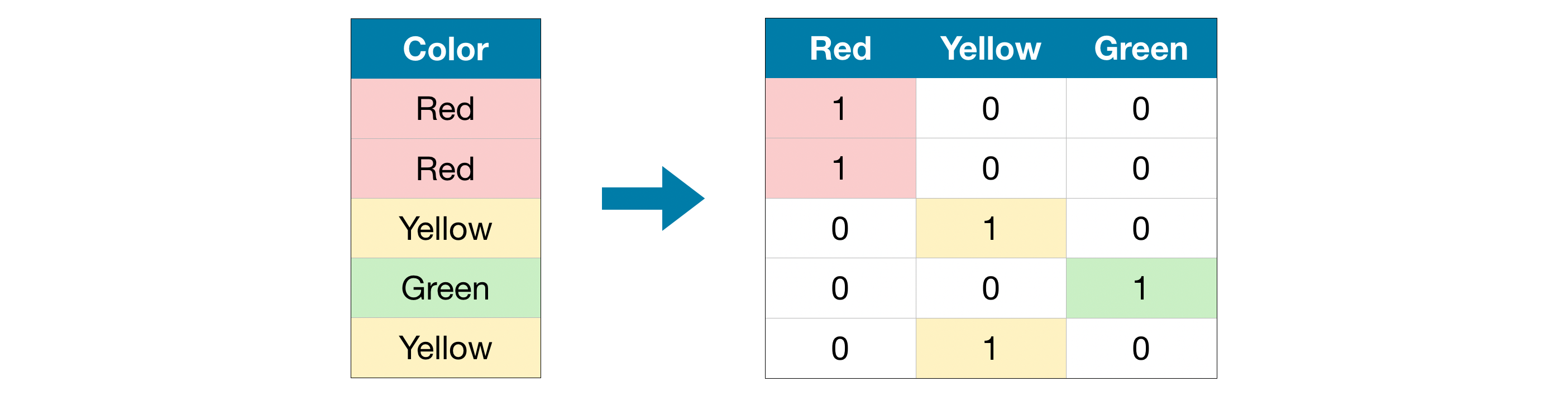
원래 데이터 집합에서 "Color"는 "Red", "Yellow", "Green"의 세가지 범주가 있는 범주형 변수다.
해당하는 One-hot-encoding에는 각 가능한 값에 대한 하나의 열과 원본 데이터 세트의 각 행에 대한 하나의 행이 포함된다. 원래 값이 "Red"인 경우 "Red"열에 1을 넣는다. 원래 값이 "Yellow"인 경우 "Yellow"열에 1을 넣는 식이다.
Ordinal encoding 과 달리 One-hot 인코딩은 범주의 순서를 가정하지 않는다.
따라서 범주 데이터에 명확한 순서가 없는 경우 (예: "Red"가 "Yello"이상도 이하도 아님) 이 접근 방식이 특히 잘 작동할 것으로 기대할 수 있다. 내재 순위가 없는 범주형 변수를 명목 변수(nominal variables)라고 한다.
범주형 변수가 많은 수의 값을 사용하는 경우 일반적으로 One-hot 인코딩이 제대로 수행되지 않는다.
(일반적으로 15개 이상의 다른 값을 사용하는 변수에는 사용하지 않음)
Example
이전 튜토리얼과 마찬가지로 Melbourne Housing dataset 으로 작업할 것이다.
import pandas as pd
from sklearn.model_selection import train_test_split
# Read the data
data = pd.read_csv('../input/melbourne-housing-snapshot/melb_data.csv')
# Separate target from predictors
y = data.Price
X = data.drop(['Price'], axis=1)
# Divide data into training and validation subsets
X_train_full, X_valid_full, y_train, y_valid = train_test_split(X, y, train_size=0.8, test_size=0.2,
random_state=0)
# Drop columns with missing values (simplest approach)
cols_with_missing = [col for col in X_train_full.columns if X_train_full[col].isnull().any()]
X_train_full.drop(cols_with_missing, axis=1, inplace=True)
X_valid_full.drop(cols_with_missing, axis=1, inplace=True)
# "Cardinality" means the number of unique values in a column
# Select categorical columns with relatively low cardinality (convenient but arbitrary)
low_cardinality_cols = [cname for cname in X_train_full.columns if X_train_full[cname].nunique() < 10 and
X_train_full[cname].dtype == "object"]
# Select numerical columns
numerical_cols = [cname for cname in X_train_full.columns if X_train_full[cname].dtype in ['int64', 'float64']]
# Keep selected columns only
my_cols = low_cardinality_cols + numerical_cols
X_train = X_train_full[my_cols].copy()
X_valid = X_valid_full[my_cols].copy()
아래 처럼 head() 메서드를 사용하여 train 데이터를 살펴본다.
X_train.head()
그다음, train data에 있는 모든 범주형 변수의 목록을 얻는다.
각 열의 데이터 유형(또는 dtype)을 확인하여 이를 수행한다.
objectdtype은 열에 텍스트가 있음을 나타낸다.(이론적으로 다른 사항이 있을 수 있지만 현재 우리의 목적에는 중요하지 않다.) 이 데이터 세트의 경우 텍스트가 있는 열은 범주형 변수를 나타낸다.
# Get list of categorical variables
s = (X_train.dtypes == 'object')
object_cols = list(s[s].index)
print("Categorical variables:")
print(object_cols)
Define Function to Measure Quality of Each Approach
범주형 변수를 처리하는 세 가지 접근 방식을 비교하기 위해 함수 score_dataset()을 정의한다.
이 함수는 랜덤 포레스트 모델에서 MAE(평균 절대 오차)를 return한다.
일반적으로 MAE가 최대한 낮기를 바라고 있다.
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error
# Function for comparing different approaches
def score_dataset(X_train, X_valid, y_train, y_valid):
model = RandomForestRegressor(n_estimators=100, random_state=0)
model.fit(X_train, y_train)
preds = model.predict(X_valid)
return mean_absolute_error(y_valid, preds)
Score from Approach 1 (Drop Categorical Variables)
select_dtypes() 메서드로 범주형 변수가 있는 열을 삭제한다.
drop_X_train = X_train.select_dtypes(exclude=['object'])
drop_X_valid = X_valid.select_dtypes(exclude=['object'])
print("MAE from Approach 1 (Drop categorical variables):")
print(score_dataset(drop_X_train, drop_X_valid, y_train, y_valid))
Score from Approach 2 (Ordinal Encoding)
Scikit-learn에는 ordinal 인코딩을 가져오는데 사용할 수 있는 OrdinalEncoder 클래스가 있다.
범주형 변수를 looping 하고 각 열에 개별적으로 ordinal encoder를 적용한다.
from sklearn.preprocessing import OrdinalEncoder
# Make copy to avoid changing original data
label_X_train = X_train.copy()
label_X_valid = X_valid.copy()
# Apply ordinal encoder to each column with categorical data
ordinal_encoder = OrdinalEncoder()
label_X_train[object_cols] = ordinal_encoder.fit_transform(X_train[object_cols])
label_X_valid[object_cols] = ordinal_encoder.transform(X_valid[object_cols])
print("MAE from Approach 2 (Ordinal Encoding):")
print(score_dataset(label_X_train, label_X_valid, y_train, y_valid))
위의 코드셀에서는 각 열에 대해 고유 값을 서로 다른 정수에 임의로 할당한다.
이는 사용자 지정 레이블을 제공하는 것보다 간단한 일반적인 접근 방식이다.
그러나 모든 ordinal 변수에 대해 더 나은 정보를 제공하는 레이블을 제공할 경우 성능이 추가로 향상될 수 있다.
Score from Approach 3 (One-Hot Encoding)
scikit-learn의 One-HotEncoder 클래스를 사용하여 one-hot encoding을 얻는다. 동작을 사용자 정의하는 데 사용할 수 있는 여러 매개변수가 있다.
- validation data에 train data 에 표시되지 않은 클래스가 포함되어 있을 때 오류를 피하기 위해 handle_uknown = 'ignore' 를 설정하고,
- sparse = False로 설정하면 인코딩된 column이 sparse matrix 대신 numpy array로 반환된다.
인코더를 사용하기 위해 one-hot encoding 하려는 범주형 열만 제공한다.
예를 들어 훈련 데이터를 인코딩하기 위해 X_train[object_cols]을 제공한다.
(아래 코드 셀의 object_cols는 범주형 데이터가 있는 열 이름의 목록이므로 X_train[object_cols]에는 훈련 세트의 모든 범주형 데이터가 포함된다.)
from sklearn.preprocessing import OneHotEncoder
# Apply one-hot encoder to each column with categorical data
OH_encoder = OneHotEncoder(handle_unknown='ignore', sparse=False)
OH_cols_train = pd.DataFrame(OH_encoder.fit_transform(X_train[object_cols]))
OH_cols_valid = pd.DataFrame(OH_encoder.transform(X_valid[object_cols]))
# One-hot encoding removed index; put it back
OH_cols_train.index = X_train.index
OH_cols_valid.index = X_valid.index
# Remove categorical columns (will replace with one-hot encoding)
num_X_train = X_train.drop(object_cols, axis=1)
num_X_valid = X_valid.drop(object_cols, axis=1)
# Add one-hot encoded columns to numerical features
OH_X_train = pd.concat([num_X_train, OH_cols_train], axis=1)
OH_X_valid = pd.concat([num_X_valid, OH_cols_valid], axis=1)
print("MAE from Approach 3 (One-Hot Encoding):")
print(score_dataset(OH_X_train, OH_X_valid, y_train, y_valid))

Which approach is best?
범주형 열 삭제(접근법 1)는 MAE점수가 가장 높기 때문에 최악의 성능을 보였다.
다른 두 가지 접근 방식의 경우 반환된 MAE점수가 매우 근접한 값이기 때문에 서로간에 의미 있는 이점은 없어보인다.
일반적으로 one-hot encoding(접근법 3)이 가장 잘 수행되고 범주형 열 삭제(접근법 1)이 일반적으로 가장 나쁜 성능을 나타내지만 경우에 따라 다른다.
Conclusion
세상은 범주형 데이터로 가득 차있다.
이 일반적인 데이터 유형을 사용하는 방법을 알면 훨씬 더 효과적인 데이터 과학자가 될 수 있다.
위에서 공부한 세 가지 접근법을 수행한 코드를 공유한다!
https://github.com/mgkim-developer/30-Days-of-ML-with-Kaggle/blob/main/30-days-of-ml-day-12-categorical-variables.ipynb
GitHub - mgkim-developer/30-Days-of-ML-with-Kaggle: 30 Days of ML with Kaggle
30 Days of ML with Kaggle. Contribute to mgkim-developer/30-Days-of-ML-with-Kaggle development by creating an account on GitHub.
github.com
'AI > Kaggle 30 Days of ML' 카테고리의 다른 글
| 30 Days of ML with Kaggle [Day 14]-XGBoost, Data Leakage (0) | 2021.08.21 |
|---|---|
| 30 Days of ML with Kaggle [Day 13]-Pipelines, Cross-Validation (0) | 2021.08.17 |
| Kaggle Intro to Machine Learning Certificate (0) | 2021.08.14 |
| 30 Days of ML with Kaggle [Day 11]-Machine Learning Competitions (0) | 2021.08.14 |
| 30 Days of ML with Kaggle [Day 10]-Underfitting and Overfitting, Random Forests (0) | 2021.08.13 |