컴퓨터 비전 (Computer Vision with Data-Centric)

컴퓨터 비전이 뭐야?
컴퓨터 비전(computer vision)이라는 단어에서 알 수 있듯, 사람의 시각과 유사한 시스템 구조를 통해 컴퓨터가 사람처럼 물체나 상황을 식별하고 해석할 수 있도록 하는 분야이다. 컴퓨터 비전에서 다루는 데이터는 이미지와 이미지 내부의 텍스트를 인지하는 영역 뿐만 아니라 Video와 3D Video도 포함된다. Video는 image Frame의 합이기 때문이다.
스마트폰이 대중화되면서 image뿐만 아니라 video data가 기하급수적으로 증가했다. 이는 컴퓨터 비전이라는 연구분야의 필요성을 증대시켰다. 한 애널리스트의 발표에 따르면, 2021년 컴퓨터 비전에서 AI 시장 규모는 159억 달러로 추정하였고, 2026년까지 해당 시장은 513억달러에 이를 것으로 예상된다. 연평균 25%이상의 성장률이라는 것이다.

컴퓨터 비전분야의 기술 및 활용
딥러닝(deep_learning)과 뉴럴 네트워크(neural network)의 발전은 컴퓨터 비전 분야의 발전을 야기했다.
제한된 영역에서만 활용되던 컴퓨터 비전이 딥러닝과 뉴럴 네트워크의 발전에 힘입어 활용범위를 넓혀가고 있다.
- 객체 분류(Object Classfication): 이미지 속 객체를 인지하여 그 class를 분류해 내는 기술로서, 컴퓨터 비전의 가장 기초적인 응용분야
- 객체 탐지 및 위치 식별(Object Detection & Localization): 이미지 또는 비디오 영상에서 객체를 식별하는 기술
- 객체 분할(Object Segmentation): 이미지 및 비디오 영상 프레임 내에서 객체를 따로 분할하여 의미 있는 부분만 분석할 수 있도록 하는 기술
- 이미지 캡셔닝(Image captioning): 이미지의 상황을 텍스트로 기술(설명)할 수 있는 기술
- 객체 추적(Object Tracking): 비디오 영상 내의 객체의 위치 변화를 추적하는 기술이다. 주로 포인트 추적(point tracking), 커널 추적(kernel tracking), 실루엣 추적(silhouette tracking)등의 방법을 사용
- 행동분류(Action Classfication): 비디오 영상 내의 객체(Object)의 행동(action)을 인식하여 Classfication하는 기술



위의 사진은 레고플레이어가 가진부품을 스캐닝하여 해당부품으로 제작가능한 작품을 추천해주는 재미있는 서비스이다.
이미지 인식기술은 예술 분야에도 널리 퍼지고 있다. Apple이 인수한 Magnus 라는 app은 카메라로 미술 작품을 인식하면, 해당 미술작품에 대한 정보와 현재 가격까지 알려준다.
이처럼 활용범위가 다양한 컴퓨터 비전연구에 어려움은 없을까?
컴퓨터 비전의 어려움, "Data Handling"
과거에 비하면 컴퓨터 비전은 비약적인 발전을 한 것이 사실이다. 하지만, 컴퓨터 비전을 다루는 것은 여전히 까다롭다.
세계 최고의 전기차 및 자율주행차 회사인 테슬라(Tesla)의 AI 디렉터 Andrej Karpathy는 트위터에서, 4년을 컴퓨터 비전을 위한 라벨링 워크플로우에 매달렸지만, 그에대한 답을 찾지 못했다고 트윗했다.
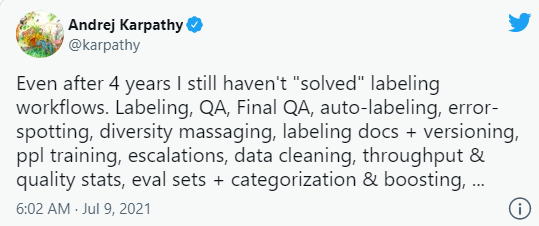
세계적인 자율주행(컴퓨터 비전) 기술을 선두하는 Tesla의 기술자가 "라벨링 워크플로우' 문제를 여전히 해결하지 못했다고 고백한 것은, 그만큼 컴퓨터 비전에서의 Data Handiling 이 어렵다는 것을 의미한다.
이미지나 영상내의 Object(객체)를 라벨링 하는 것이 라벨링 작업의 전부라고 생각할 수 있다. 하지만 라벨링 워크플로우(Labeling workflows)는 많은 작업을 수반하고 있다는 것을 알 수 있다.
라벨링 워크플로우(Labeling workflows)
- 데이터에 대한 라벨링 기준 마련
- 라벨링 작업 결과물에 대한 QA(품질관리) 및 피드백 수집 과정 구축
- 라벨러 훈과 퍼포먼스 측정을 포함하는 인력관리
- 라벨링 과정중 이슈 발생시 커뮤니케이션 비용 관리
- 라벨링을 통해 구축된 데이터셋의 버전관리
라벨링 워크플로우에는 이러한 항목들이 포함된다. 여기에 나열한 것은 워크플로우 범위중 일부다!
지금까지 이미지나 영상 데이터의 라벨링 작업은 모델링모다 덜 중요한 것이라고 치부되고 있다.
Tesla, 자율주행에서 가장 두각을 보이는 기업의 기술자가 라벨링 워크플로우의 중요성을 지적한 것은, 컴퓨터비전이 정말 상용화 되기 위해서는 우리가 주목해야할 부분은 데이터 handling이라고 해석할 수 있다.
최근 coursera의 창업자이자 스탠포드대학의 교수인 Andrew Ng도 model을 고정시키고 Data 품질을 향상시켜서 더 좋은 결과를 얻는 것이 목표인 competition을 개최했는데, Andrew Ng가 Data 중심으로 AI가 발전해야 한다고 주장한 것과 일맥상통한다. 나또한 동의하는 바이고, Andrew Ng의 Chat에도 참여하며 발표를 청강했는데 너무 인상깊었다.
아무튼, 데이터에 대한 중요성은 지금보다 훨씬더 강조되어야 하는 것이 사실이다.
다시 컴퓨터 비전으로 돌아와서, 컴퓨터비전에서 데이터 문제가 특히 어려운 이유가 무엇일까? 두가지로 나누어 자세히 알아보자.

1. 사람은 이미지를 인식하지만, 컴퓨터는 숫자를 인식한다.
사람이 이미지를 인식하는 과정이 무의식적 또는 잠재 의식적으로 진행되기 때문에, 흔히 컴퓨터가 비전을 처리하는 방식또한 매우 간단할 거라고 착각 할 수 있다.
하지만, 컴퓨터 비전의 뉴럴 네트워크를 들여다 보면, 그 복잡성은 엄청나다!
대뇌피질의 상당부분은 이미지 프로세싱 처리에 전념하게 되는데, 이것이 인간과 컴퓨터의 이미지 처리방식차이이다.
인간은 매우 시각적이고 직관적인 방식으로 이미지를 인식하는 반면, 컴퓨터는 이미지를 그자체로 인식하는 것이 아닌 이미지의 모든 부분을 개별 픽셀로 환산하여 숫자로 인식한다. 이는 이미지를 인식 할 때마다 처리해야하는 데이터의 양이 많다는 것을 의미한다.

EXPLANING AND HARNESSING ADVERSARIAL EXAMPLES라는 논문을 보면 다음과 같은 내용이 있다.

초기에는 57.7%의 confidence로 왼쪽사진을 panda라고 인식했다.
그리고 가운데 보이는 노이즈사진의 0.07배에 해당하는 노이즈를 초기사진에 합성시켯다.
그랫더니 오른쪽 사진을 인식한 결과는 무려 99.3%의 confidence로 "gibbon" (긴팔 원숭이)라고 인식했다.
우리가 눈으로 보기에는 왼쪽사진이나 합성후의 오른쪽 사진이나 별반 다를거 없는 사진으로 보이지만,
컴퓨터비전의 특성상, 이미지의 모든 부분을 개별 픽셀로 환산하여 숫자로 인식한다는 한계점때문에 나타난 현상이다.
2. 컴퓨터 비전 시스템은 사람보다 더 많은 데이터를 필요로 한다.
현재의 컴퓨터 비전 시스템의 이미지 처리 능력을 사람과 비슷하게 구현하려면, 사람이 필요로 하는 것보다 훨씬 더 많은 데이터가 필요하다. 현재 컴퓨터 비전 분야를 주도하는 머신러닝 기법은 지도학습이다.
지도학습은 feature가 라벨링 되어있는 데이터를 기반으로 학습을 한다.
최근에는 지도학습을 바탕으로 하되, 라벨링이 되지 않은 추가 input data를 이용하여 학습시키며 모델의 성능을 개선시켜 나가고 있다.
데이터의 퀄리티가 모델의 성능을 결정한다해도 과언이 아니다. 학습에 사용된 train data set이 test data set과 얼마나 유사한지가 중요한 포인트가 된다.
즉, 다양한 실제 상황에 대해 데이터로 준비해서 학습시켜야 성능이 좋아진다.
하지만, 실제로 이런 다양한 상황의 데이터를 모두 수집해서 학습시키기는 현실적으로 쉽지 않다.
현재 테슬라는 대규모 자체 인력과 자본을 기반으로 Data-centric(데이터 중심)방법론을 이용하고 있다.
자주 일어나지는 않지만, 실생활에서 충분히 일어날 수 있는 상황 등을 221가지로 추려 나열한 후, 해당 케이스의 데이터를 집중적으로 확보했다고 하는데, 이렇게 흔하게 일어나지 않는 상황들을 edge-case(엣지 케이스) 라고 한다.
해당 데이터를 이용해서 백테스팅을(shadow mode)를 한 후 검증이 완료되면, 실제 배포로 이어지고, 그 이후 Tesla운행자로부터 추가되는 새로운 데이터는 또다시 새롭게 Data로 추가되어 백테스팅(shadow mode)를 거친 후 모델의 성능을 높히게 된다. 이러한 방법은 전형적인 Data-centric(데이터 중심)방법론 이다.
컴퓨터 비전 학습용 Data set
컴퓨터 기술의 발전은 오픈소스 및 공개된 데이터셋 덕분에 이루어져왔다.
오픈소스와 공개 데이터셋은 컴퓨터 발전에 많은 영향을 끼쳤다. 현재까지도 컴퓨터 비전 프로젝트에 많이 쓰이는 데이터셋을 몇가지 소개한다.
10개의 카테고리로 분류되는 70,000개의 흑백 이미지로 구성된 데이터 셋이다.
GitHub - zalandoresearch/fashion-mnist: A MNIST-like fashion product database. Benchmark
A MNIST-like fashion product database. Benchmark :point_down: - GitHub - zalandoresearch/fashion-mnist: A MNIST-like fashion product database. Benchmark
github.com

CIFAR-10 데이터셋은 머신러닝 연구에 가장 활발히 사용되는 데이터셋이다.
10개의 클래스(airplane, automobile, bird, cat, deer, dog, frog, horse, ship, truck)로 이루어진 60,000개의 이미지 데이터셋이다.
CIFAR-10 and CIFAR-100 datasets
< Back to Alex Krizhevsky's home page The CIFAR-10 and CIFAR-100 are labeled subsets of the 80 million tiny images dataset. They were collected by Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton. The CIFAR-10 dataset The CIFAR-10 dataset consists of 60000
www.cs.toronto.edu

MS COCO는 (Common Objects in Context)의 줄임말 이다.
딥러닝 프로그램을 교육하는데 많이 사용되는 오픈소스 데이터베이스 중 하나이다.
객체 탐지(Object Detection), 분할(Segmentation), 포인터(Keypoint Detection)등에 쓰인다.
COCO데이터 저장방식이 궁굼하면 이 링크를 참고하자.
COCO - Common Objects in Context
cocodataset.org

ImageNet은 1,400만개 이상의 공개 이미지 데이터 셋이다.
일상생활에서 볼 수 있는 거의 모든 종류의 이미지를 포함한다.
ImageNet
Mar 11 2021. ImageNet website update.
image-net.org

구글이 머신러닝을 위해 2016년에 공개한 데이터셋이다.
이미지에 주석이 달려있고, 데이터에 전문 라벨러들이 라벨링을 검수한 이미지들을 포함한다.
데이터셋은 V1부터 지속적으로 업데이트 되고있다.
이미지 상의 Object(객체)간 관계를 보여주는 라벨링, 이미지를 설명하는 캡션 과 음성 나레이션이 추가되어있어서, 이미지와 캡션사이를 연결하는 복잡한 모델을 만드는데에 유용하게 사용되고 있다. (Google AI blog에 가면 더 자세한 정보를 얻을 수 있다.)
Open Images V6 — Now Featuring Localized Narratives
Posted by Jordi Pont-Tuset, Research Scientist, Google Research Open Images is the largest annotated image dataset in many regards, for...
ai.googleblog.com
Projects – opensource.google
Learn about all our projects.
opensource.google



'AI > 머신러닝과 딥러닝' 카테고리의 다른 글
| Predict modeling process (0) | 2021.09.03 |
|---|---|
| 과적합(overfitting) 방지를 위한 데이터셋 분리 (0) | 2021.08.12 |