스트림의 최종연산
Stream의 연산에는 중간연산과 최종연산이 있다.
- 중간연산은 n번 가능하다. 중간연산은 스트림을 반환한다.
- limit(), skip(), filter(), distinct(), map(), faltMapt(), peek()
- 최종연산은 1번 가능하다. 최종연산은 스트림의 요소를 소모한다. 그래서 최종연산을 하고 나면 스트림이 닫힌다. 최종연산은 int, boolean, Optional 등을 반환한다.
- forEach(), allMatch(), anyMatch(), noneMatch(), reduce(), collect(), findFirst(), findAny()
스트림의 최종연산 - forEach()
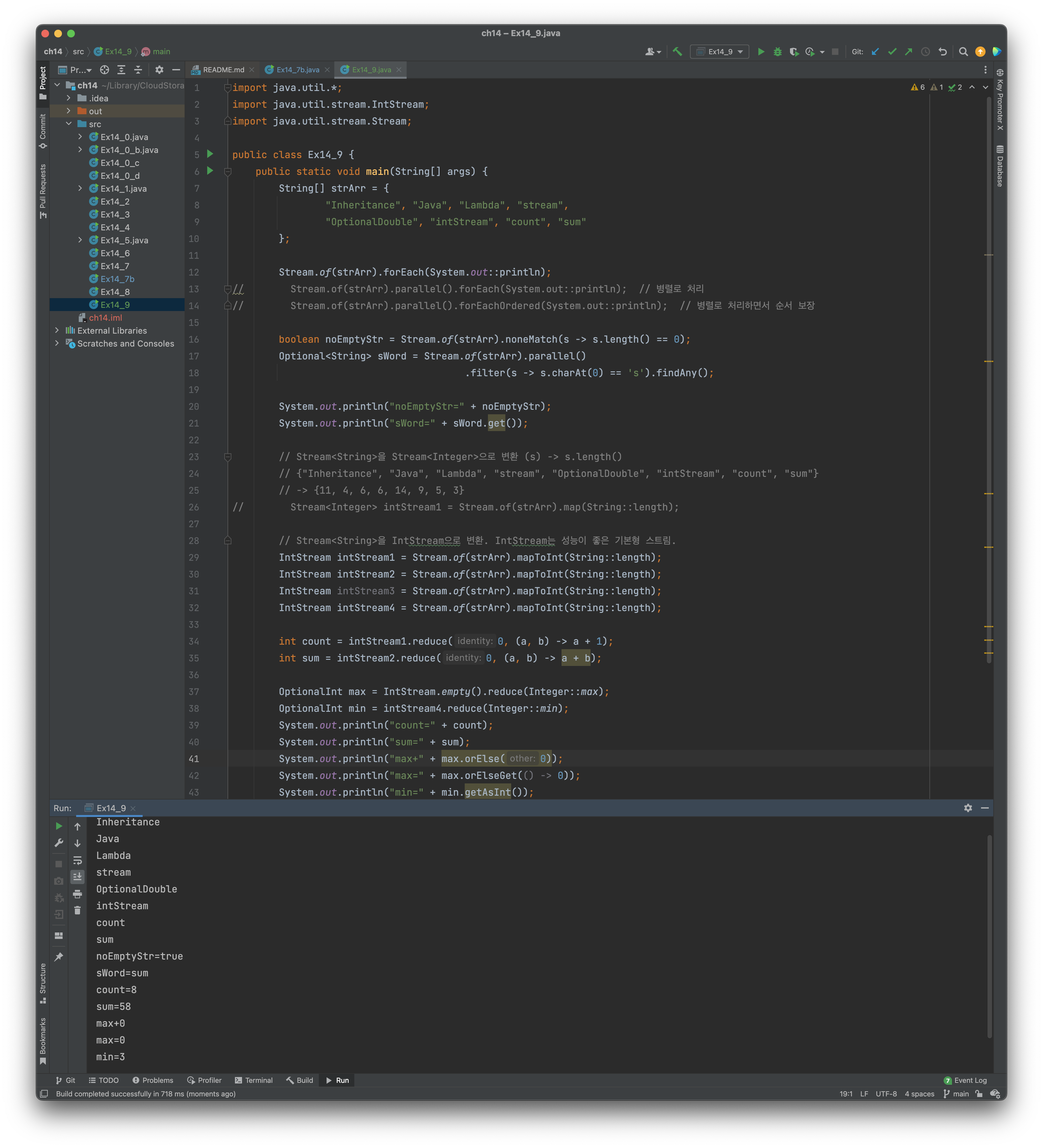
- 스트림의 모든 요소에 지정된 작업을 수행 - forEach(), forEachOrdered()

forEach()와 forEachOrdered()는 스트림의 모든 요소에 지정된 작업을 수행하는 최종연산이다.
둘의 차이점은,
forEach()는 병렬스트림인 경우 순서가 보장되지 않고,
forEachOrdered()는 병렬스트림인 경우에도 순서가 보장된다는 점이다.
IntStream.range(1, 10).sequential().forEach(System.out:print);
에서 range(1, 10)은 1~9이다. 그리고 출력하는 것이다.
sequential()은 직렬 스트림이다.
스트림의 작업을 직렬로 처리하는 것이다.
parallel()은 병렬 스트림이다.
스트림의 작업을 병렬로 처리하는 것이다. 여러 쓰레드가 나눠서 작업을 한다. 데이터가 많을 때는 더 빠른 결과를 얻기 위해서 병렬로 처리하는 것이다.
스트림은 기본적으로 직렬 스트림이어서 sequential()을 생략해도 된다.
그런데 만약에 parallel()을 붙이면, 병렬로 처리된다.
그러면 forEach()의 결과가 123456789가 아니라 683295714 이렇게 섞여서 나온다.
직렬때는 하나의 쓰레드가 순서대로 처리하니까 순서유지가 되는데,
병렬로 처리할 때는 여러 쓰레드가 나눠 처리하기 때문에 순서가 보장되지 않는다.
기본적으로 forEach()와 forEachOrdered()는 같은데, 병렬일때 차이가 발생한다.
forEach()는 병렬스트림인 경우 순서가 보장되지 않고,
forEachOrdered()는 병렬스트림인 경우에도 순서가 보장된다.
이러한 차이점이 있다.
스트림의 최종연산 - 조건 검사
- 조건 검사 - allMatch(), anyMatch(), noneMatch()
이 메서드들은 파라미터로 Predicate를 받는다. 즉, 조건식을 받는다.
- boolean allMatch(predicate) - 모든 요소가 조건을 만족시키면 true
- boolean anyMatch(predicate) - 한 요소라도 조건을 만족시키면 true
- boolean noneMatch(predicate) - 모든 요소가 조건을 만족시키지 않으면 true
메서드가 사용된 예를 살펴보자.
학생에 대한 스트림이 있을 때, 거기 학생들의 총점이 100점 이하인 사람들이 있는지 확인하는 것이다.
anyMatch()이므로 어느 한명이라도 100점 이하라면 true를 반환한다.
- 조건에 일치하는 요소 찾기 - findFirst(), findAny()
findFirst()는 어떤 조건에 맞는 요소를 하나 찾는 것이다. 순차 스트림에 사용한다.
조건에 맞는 요소가 없을 수도 있기 때문에, Optional<T>로 반환된다. 결과가 null일 수 있다는 것이다.
처음부터 쭉 찾아보다가 처음 발견하는 하나를 반환하는 것이다.
findAny() 같은 경우도 findFirst()와 비슷한데 병렬 스트림에 사용하는 것이다.
병렬 스트림에 사용되는 것이므로 여러 쓰레드 중에서 먼저 조건에 맞는 것을 발견한 쓰레드가 반환을 하는 것이다.
사용 예시를 보면,
이렇게 filter()랑 같이 사용한다.
학생 스트림에서 그 학생의 총점이 100점 이하인 학생 중에 첫번째 학생(요소)를 반환한다.
조건이 만족시키는 것이 없을 수 있으므로(null일 수 있으므로) Optional로 반환한다.
병렬 스트림일 때는 findAny()를 사용한다.
스트림의 최종 연산 - reduce()
- 스트림의 요소를 하나씩 줄여가며 누적연산(accumulator) 수행 - reduce()
reduce() 스트림의 요소를 하나씩 줄여가면서 누적연산(accumalate)한다.
reduce()는 여러가지로 오버로딩 되어잇다.

identity는 초기값이다.
accumulator는 이전 연산결과와 스트림의 요소에 수행할 연산이다.
combiner는 병렬처리된 결과를 합치는데 사용할 연산이다.(병렬 스트림)
만약 초기값(identity)을 주면, 스트림의 요소가 하나도 없으면 identity를 반환하게 된다.
그런데, 초기값이 없으면, 만약 비어있는 스트림이라면 결과가 null일 수 있다.
그래서 초기값을 주지 않는 Optional<T> reduce(BinaryOperator<T> accumulator)는 Optional을 반환한다.
사용방법은 아래와 같다.

요소가 몇개있는지 확인하려면 초기값0에 요소를 꺼낼때 마다 1씩 더하면 된다.
위의 count코드는 요소갯수를 반환한다.
요소를 더하려면, 초기값0에 요소를 꺼낼 때 마다 누적하여 더하면 된다.
위의 sum 코드는 요소의 총합을 반환한다.
요소의 최대값을 구하려면, 초기값으로 최소값을 주고, 비교하며 큰 값을 반환하면 된다.
위의 코드에서 max는 최대값을 반환한다.
반대로 최소값은 초기값을 최대값으로 주고, 비교하며 작은 값을 반환하면 된다.
위의 코드에서 min은 최소값을 반환한다.
실제로 스트림의 최종연산은 reduce()를 이용하여 만들어져 있다.
'JAVA' 카테고리의 다른 글
| 스트림의 그룹화와 분할 (0) | 2022.12.02 |
|---|---|
| collect()와 Collectors (0) | 2022.11.30 |
| Optional<T> (0) | 2022.11.22 |
| 스트림의 중간연산(2) (0) | 2022.11.19 |
| 스트림의 중간연산(1) (0) | 2022.11.19 |
댓글을 사용할 수 없습니다.