HashMap (1)
HashMap과 Hashtable - 순서 X, 중복(키X, 값O)
- Map인터페이스를 구현. 데이터를 키와 값의 쌍으로 저장

HashMap과 Hashtable은 둘다 Map인터페이스를 구현한 클래스이다.
데이터를 key와 value의 쌍으로 저장한다. (key, value)
Set과 달리 저장순서를 유지하지 않는다. 중복의 경우에는 key는 중복 허용하지 않고, value는 중복을 허용한다.
Hashtable은 옛날버전이다. HashMap과 거의 동일하다.
다만, Hashtable은 동기화가 되있고,
HashMap은 동기화가 되어있지 않다.
즉, 두 클래스 차이는 동기화 유무에 있다. (자세한 내용은 13장 쓰레드에서 알아보자.)
TreeMap은, TreeSet과 같은 특성을 가지고 있다. (이진 탐색 트리)
Map은 원래 순서를 유지 하지 않는데,
만약 순서를 유지하면서 Map을 사용해야 하면, LinkedHashMap을 사용하면 된다.
HashMap
- Map인터페이스를 구현한 대표적인 컬렉션 클래스
- 순서를 유지하려면, LinkedHashMap클래스를 사용하면 된다.
TreeMap
- 범위 검색과 정렬에 유리한 컬렉션 클래스
- HashMap보다 데이터 추가, 삭제에 시간이 더 걸림
HashMap의 키(key)와 값(value)
- 해싱(hashing)기법으로 데이터를 저장. 데이터가 많아도 검색이 빠르다.
- Map인터페이스를 구현. 데이터를 키와 값의 쌍으로 저장
HashMap은 해싱기법으로 데이터를 저장하기 때문에, 데이터가 많아도 검색이 빠르다.
그리고 key는 중복을 허용하지 않고, value는 중복을 허용한다.
오른쪽 예시를 보자.
map.put으로 데이터를 저장하는데, 데이터를 3쌍 저장시도를 하지만, 최종 저장 결과는 2개이다.
myID 1234는 잘 저장되고, asdf 1111도 잘저장된다. 그런데 세번쪠에 저장하려는 데이터의 key가 이미 저장되있는 key중 하나인 asdf이다. 이러면 에러가 나서 저장이 안되는게 아니라 기존에 저장되있던 asdf의 value를 새로운 값으로 바꾼다.
즉, asdf 1234로 저장되어, 최종 저장결과는 myId 1234, asdf 1234이다.
HashMap클래스를 보면,
안에 Entry[] table이라는 배열이 있다.
key와 value값이 해당 배열에 저장된다.
전에 언급했듯, Entry는 key와 value값쌍을 칭한다.
key와 value를 따로따로 객체 배열로 저장할 수 있지만, 이렇게 하는 것 보다는,
key와 value를 하나로 묶은 다음에, 묶음에 배열을 선언하는 것이 더 객체지향적인 코드이다.
사실 현재 JDK 버전이 올라가면서 실제 소스를 찾아보면,
객체지향적인 코드가 오른쪽과 달리 조금 변경되어 있다.
위의 표는 옛날 코드이다. 객체지향을 이해하는데에는 표의 코드가 더 적절하다고 생각되어 필자가 그렇게 작성한 것이다.
해싱(hashing)
해싱의 원리를 예시로 알아보자.
간호사가, "많은 환자들의 차트를 어떻게 관리할까?" 라고 고민을 하다가 좋은 방법을 생각해냈다.
"출생년도 별로 분류해서 캐비넷에 저장하자" 라고 생각하고,
출생연도별로 다 나누어놓았다.
그러면, 누군가 "환자정보좀 찾아주세요. 주문번호는 72xxxxx-xxxx이에요"라고 요청을 하면,
간호사는 "72xxxxx-xxxx이면 캐비넷 7번 서랍에 있겠네"라고 생각할 수 있다.
이것이 해시함수가 하는 일이다.
어떤 key를 넣으면 배열의 인덱스를 알려준다. 즉, 저장위치를 알려준다.
key를 넣어 반환된 배열의 인덱스를 해시코드라고 하는 것이다.
해시코드는 저장위치다.
해시함수에 같은 key를 넣으면 항상 같은 해시코드가 나와야 한다.
해시코드를 이용하면 해당 key가 저장된 위치를 쉽게 찾을 수 있다.
즉, 해싱은 해시함수를 이용해서 데이터 저장&읽기를 하는 것이다.
해싱이란,
- 해시함수(hash function)로 해시테이블(hash table)에 데이터를 저장, 검색
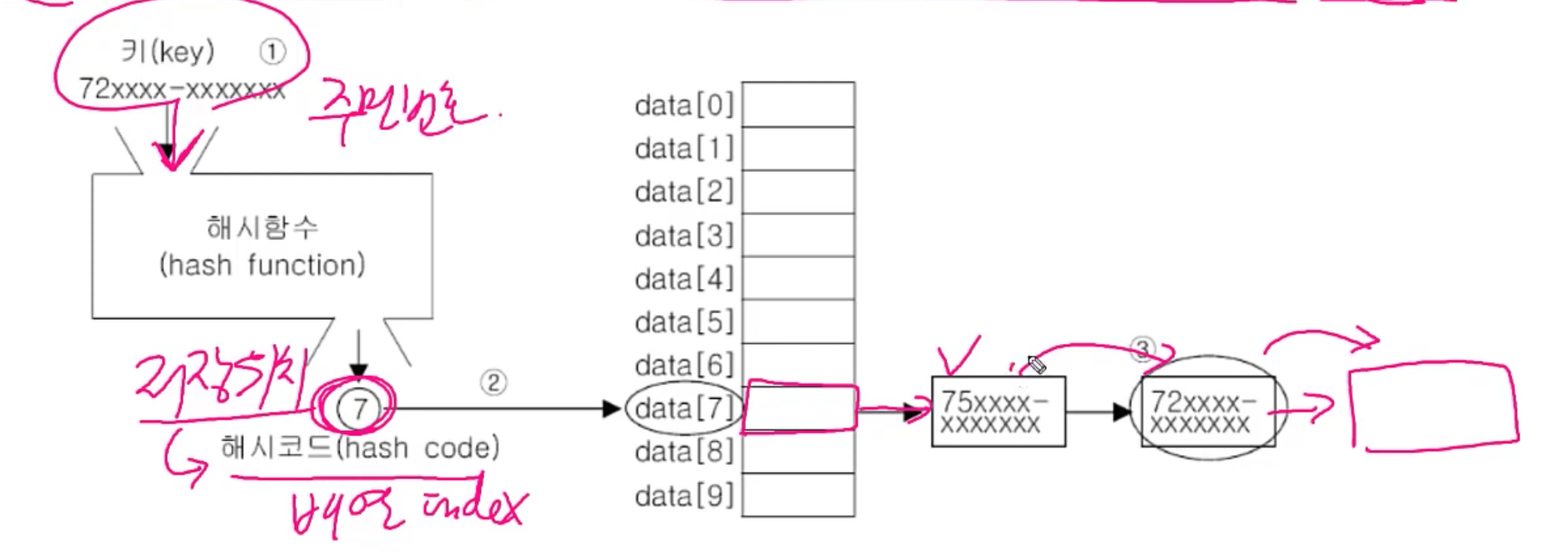
해시함수에다가 key를 넣으면, key가 어디 저장되어있는지 해시코드(저장위치)를 반환한다.
해시코드는 배열의 인덱스인데, 배열은 인덱스만 알면 한번에 찾을 수 있다.
그래서 그 인덱스로 찾아가서 데이터를 하나씩 보는 것이다. 거기에 있는 데이터를 하나씩 살펴보고, 일치하는 데이터를 찾게 된다.
- 해시테이블은 배열과 링크드 리스트가 조합된 형태
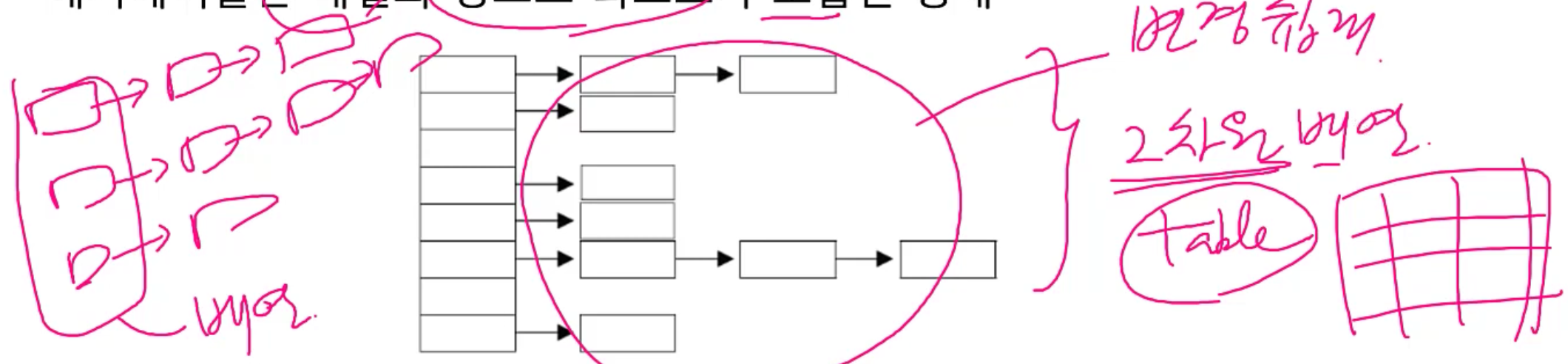
데이터를 저장하는 공간을 해시테이블이라고 하는 것이다.
2차원 배열형태로 생겨서 테이블이라고 하는 것이다.
이것은 링크드 리스트 여러개를 묶어 놓은 것이다.
링크드 리스트로 구성한 이유는 변경이 용이하도록 하기 위함이다.
해시테이블은,
배열은 인덱스만 알면 접근이 쉽다는 장점 + 링크드리스트의 변경이 용이하다는 장점 두개를 혼합한 것이다.
이렇게 하면, 분류된 데이터가 링크드리스트에 담겨져 있으므로 검색속도가 상당히 빨라진다.
해싱은 해시함수를 이용한 것이기 때문에, 해시함수의 성능이 중요한데,
우리는 Objects.hash() 메서드를 이용해서 작성하면 된다.
Hashtable, HashMap, HashSet 클래스들은 hashcode() 메서드를 사용하는데,
hashcode()메서드를 어떻게 오버라이딩 하냐면,
Objects.hash()를 이용해서 hash함수를 작성하면 된다.
해시테이블에 저장된 데이터를 가져오는 과정
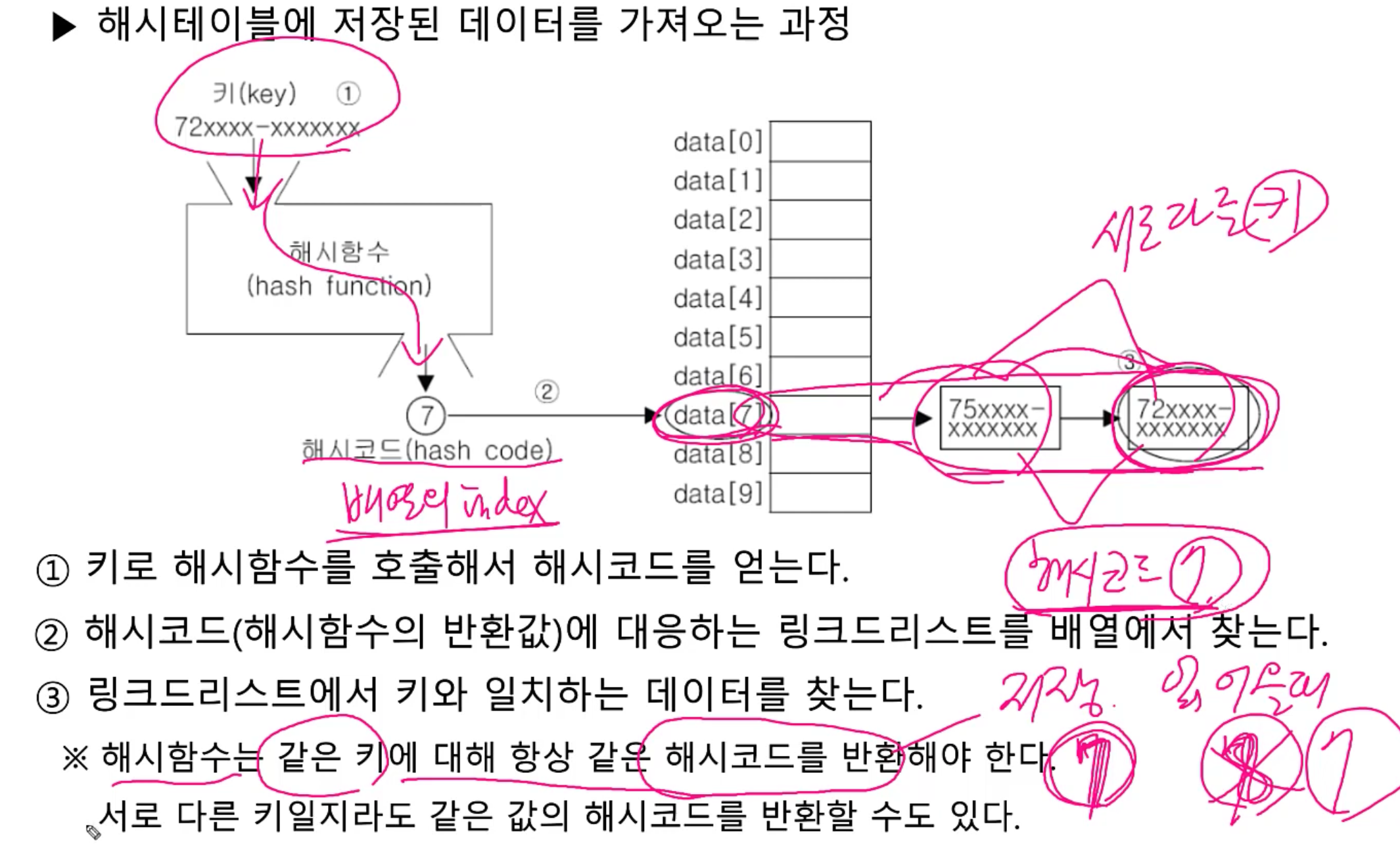
1. 키로 해시함수를 호출해서 해시코드(링크드리스트가 담긴 배열의 인덱스)를 얻는다.
2. 해시코드(해시함수의 반환값)에 대응하는 링크드리스트를 배열에서 찾는다.
3. 링크드리스트에서 키와 일치하는 데이터를 찾는다.
※ 해시함수는 같은 키에 대해 항상 같은 해시코드를 반환해야한다. 서로 다른 키일지라도 같은 값의 해시코드를 반환할 수도 있다.
서로 다른 key일지라도, 둘다 같이 캐비닛에 있으면, 같은 값의 해시코드를 반환할 수도 있다.
'JAVA' 카테고리의 다른 글
| Collections클래스, 컬렉션 클래스 요약 (0) | 2022.05.03 |
|---|---|
| HashMap (2) (0) | 2022.05.03 |
| TreeSet (2) (0) | 2022.05.02 |
| TreeSet (1) (0) | 2022.05.02 |
| HashSet (2) (0) | 2022.05.02 |
댓글을 사용할 수 없습니다.